Занавески на балкон: 5 лучших вариантов с пошаговыми инструкциями
Независимо от того, какие функции выполняет балкон (служит складом для консервации, рабочим кабинетом, дополнением жилплощади или временной стоянкой для детских колясок), по большей части он состоит из стекол. И чтобы это помещение выглядело завершенным, балконные окна следует грамотно обрамить текстилем. Мы, разумеется, говорим о занавесках.

Занавески на балкон
Важнейшим моментом современного оформления балконов считаются грамотно подобранные шторы, которые гармонично сочетаются с общим интерьером. В зависимости от того, каково назначение данного помещения, сколько в нем окон и как вообще оформлена прилегающая комната, к занавескам выдвигаются различные требования, в том числе касающиеся расцветки, фактуры и размеров. Чтобы помещение выглядело более оригинально, занавески на балкон можно сделать самостоятельно. Подобная работа не представляет собой ничего сложного – по сути, для нее потребуется лишь швейная машинка, навыки работы с ней и ножницы.

Декоративные занавески с тесьмой

Интересные шторы на балконе
Содержание пошаговой инструкции:
- 1 Что нужно учитывать?
- 2 Вариант №1. Изготавливаем римские шторы
- 2.1 Этап первый. Подготавливаем все необходимое
- 2.2 Этап второй. Изготовление
- 2.3 Видео – Римская штора: простой метод
- 3 Вариант №2. Делаем жалюзи из остатков флизелиновых обоев
- 3.1 Видео – Бумажные жалюзи
- 4 Вариант №3. Делаем японские шторы
- 4.1 Видео – Японские панели
- 5 Вариант №4. Изготавливаем нитяную штору
- 5.1 Видео – Нитяные шторы в дизайне интерьера
Что нужно учитывать?
До того как приступать к работе, следует определиться с типом занавесок и их дизайном. Отличный вариант для балкона – это римские шторы, представляющие собой прямые отрезки ткани, которые поднимаются посредством складывания. Вариаций в таком случае масса: можете сделать изысканные французские треугольники или отдать предпочтение красивому кружеву, пошить цельную конструкцию, утяжелив ее вдоль створок, или использовать драпировку. Как бы то ни было, главное преимущество любых римских штор – это удобство.

Выбор цвета ткани для балконных занавесок

Шторы в полосочку на балконе
Обратите внимание! Эти занавески не будут развеваться на ветру либо мешать открывать балконные окна. Кроме того, подобное дизайнерское решение позволяет значительно сэкономить.

Римские шторы на липучке

Римские шторы для окон на балкон
Дело в том, что для римских занавесок требуется небольшое количество материала, поэтому вы вполне можете использовать дорогостоящий оригинальный текстиль. Что же касается массивных портьерных конструкций или штор, состоящих из нескольких слоев, то от них в случае с балконом желательно отказаться, ведь они будут заниматься значительную часть и без того ограниченного пространства. Вместе с тем, плотный светонепроницаемый материал тоже лучше не использовать, т. к. балкон, в первую очередь, необходим для пропуска воздуха и света.

Ткани для балконных занавесок: лучший выбор
Наконец, отлично будут выглядеть и светлые занавески в японском стиле, выполненные из бамбука либо льна.

Классические занавески для лоджии и балкона
Вариант №1. Изготавливаем римские шторы

На фото римские шторы из полотна коричневого оттенка
Начнем с того, что они могут быть цельными или состоящими сразу из нескольких полотен. Во втором случае каждую из занавесок нужно крепить к отдельному карнизу. Если вы новичок, то лучше пошейте цельный вариант – это поможет вникнуть в суть процесса, уяснить принцип работы карниза и крепежей.

Можно изготовить шторы из полупрозрачной ткани

Подбирайте материал в соответствии со своими предпочтениями
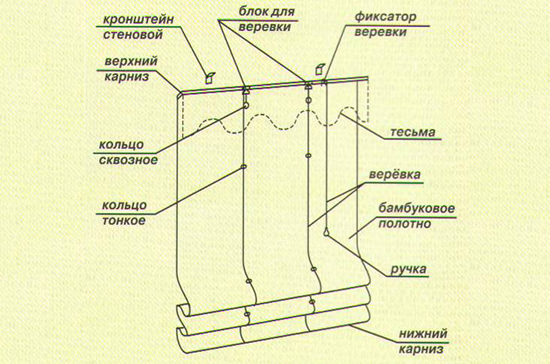
Схема римской шторы
Обратите внимание! Зачастую длина римских штор соответствует высоте потолка, но при желании можете сделать их короче.

Варианты римских штор
Этап первый. Подготавливаем все необходимое
В процессе изготовления понадобится:
- ткань (а также материал для подкладки в случае необходимости);
- крюки на винтовой ножке;
- лента с липучкой;
- шурупы, небольшие гвозди;
- прутья диаметром 0,4-0,5 см (деревянные либо пластиковые), длина которых на 3 см меньше предполагаемой ширины занавески (около 7-8 штук);
- брусок 2,5х5 см (такой же длины, как ширина занавески) для подвешивания;
- маленькие пластмассовые кольца (диаметр – 1-1,2 см) для каждой кулисы; в них вы впоследствии проденете шнуры;
- утяжеляющая планка;
- 3 отрезка нейлонового шнура (1 ширина + 2 длины занавески).
После подготовки всего необходимого можете смело начинать работу.
Этап второй. Изготовление
Шаг 1. Вначале измерьте проем. К полученным цифрам добавьте 6-7 см на швы по бокам и 12-15 см на припуски. Как правило, припуски по высоте соответствуют 20% шторы. Далее продекатируйте ткань во избежание ошибок или усадки материала при пошиве: поместите на несколько минут в воду, после чего высушите и проутюжьте.

Схема расчета ткани

Схема изготовления римской шторы
Если говорить о складках, то их число/размеры зависят, прежде всего, от длины окна. Для определения нужного шага между складками можете воспользоваться приведенной ниже таблицей.

Таблица расчета количества и размеров складок
Также отметим, что еще одним секретом изготовления этих штор является грамотный расчет «карманов-складок».
Шаг 2. Наметьте на тыльной стороне будущие подвороты, складки и месторасположение колец в соответствии со схемой выше. При этом необходимо, чтобы между складками везде был одинаковый шаг – тогда готовое изделие будет красиво драпироваться.
Шаг 3. На боковых краях выполните двойную подгибку. Отрегулируйте степень натяжения шнура, чтобы строчка не стягивала бока.

На фото правильная обработка края материала
Шаг 4. Используя мебельный степлер или маленькие гвозди, зафиксируйте липучку на нижней части бруска с прикрепленным к нему полотном. Произведите обработку верхнего среза, после чего пришейте туда оставшийся кусок липучки – так в случае необходимости вы сможете с легкостью снимать полотно, чтобы постирать.

Липучка пришита, края качественно обработаны
Брусок, который послужит карнизом, заранее обработайте краской требуемого цвета. Хотя вместо бруска можете взять ламбрикенную планку с липучками (такие покупают с кронштейнами для потолка).

Крупным планом показан брусок
Шаг 5. Сделайте подворот в нижней части римки и создайте кулиску такой ширины, чтобы в сформировавшийся «карман» можно было засунуть утяжеляющую планку. Как вариант – утяжелителем может послужить плоский профиль (из алюминия), длина которого была бы на 1-2 см меньше, чем карниза.
Важно, чтобы цвет утяжелителя соответствовал окрасу ткани. Купить такой профиль можно в любом строительном магазине.

На фото показано, как прикрепить утяжелители
Шаг 6. Пристрочите по изнанке полотна кайму, а в карманы, образовавшиеся вследствие этого, вставьте штыри. Заделайте отверстия, но при этом сшивайте края лишь с одной стороны – это позволит вынимать штыри перед стиркой и вставлять их обратно.
Также важно, чтобы штыри не разорвали полотно. В идеале должны использоваться небольшие пластиковые прутья либо корсетные вставки (последние можно найти в любом магазине, специализирующемся на швейной фурнитуре). Вставлять такие корсетные вставки нужно следующим образом: вначале нарежьте их на отрезки требуемой длины, оставив небольшой запас, и нагрейте утюгом через ткань, затем на несколько суток положите под пресс для полного распрямления (дело в том, что такие вставки продаются рулонами пометражно). После этого можете вставлять их в карманы шторы. Наконец, еще одним вариантом может быть применение металлической проволоки, но при условии, что пруты ровные и выполнены из «нержавейки».
Шаг 7. Разметьте расположение колец и пришейте их вручную, действуя в соответствии со схемой. Для фиксации колец на бруске используйте гвозди.

Схема расположения колец
Обратите внимание! Кольца должны располагаться симметрично по отношению к середине занавески. Кроме того, крайние кольца нужно крепить примерно в 7-10 см от краев.
Шаг 8. Прикрепите липучками полотно к бруску. Крепежный элемент шнура зафиксируйте на раме. Продевайте в кольца шнур, двигаясь снизу вверх, и на нижнем завяжите узел. Можете дополнительно использовать клей для повышения прочности.
Шаг 9. Продевая шнур через остальные кольца, с каждым новым рядом проделывайте описанные выше действия. В итоге шнуры должны выходить на одну сторону посредством верхних колец. Туго затяните все шнуры, после чего распределите складки по занавеске. Используя тесемки, зафиксируйте складки в данном положении.

Шнуры продеты в кольца

На фото показано, как продеть шнуры

Процесс изготовления штор. Протяните веревки через отверстия на поперечных планках. Когда этот этап пройден, протяните веревки через дырки в карнизе и зафиксируйте его
Шаг 10. Установите брусок на оконную раму или выше нее, снимите тесемки – римка после этого должна опуститься. Подкорректируйте натяжение шнуров и, собрав их в пучок, свяжите за последним кольцом в узел. Далее продевайте их через подъемную ручку и в полуметре от узла завяжите другой. Осторожно обрежьте концы за вторым узлом. Все, работа закончена!

Штора в свернутом виде

Готовые шторы в развернутом виде

Готовая римская штора
Видео – Римская штора: простой метод
Вариант №2. Делаем жалюзи из остатков флизелиновых обоев

Жалюзи бумажные

Бумажные занавески темного цвета
Еще один вариант, который вполне можно использовать для украшения балкона. После ремонта многие не знают, куда пристроить остатки обоев, мы же предлагаем сделать из них оригинальные бумажные жалюзи. К слову, первыми бумажные занавески начали делать китайские домохозяйки для украшения спален, а вы можете использовать данный вариант на балконе.
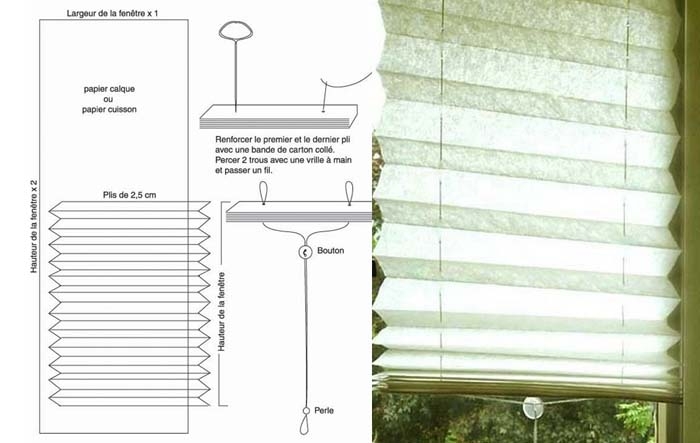
Схема изготовления жалюзи

Шторы бумажные
Вначале измерьте ширину/высоту окон. Затем добавьте к высоте еще примерно 25%, ведь обои будут складываться в «гармошку».

Процесс снятия мерок
По завершению замеров подготовьте:
- обои;
- скотч (обычный и двухсторонний);
- дырокол (можно заменить шилом);
- клей;
- линейку;
- большие бусины;
- ножницы;
- ленту (ее цвет должен соответствовать цвету обоев);
- фиксатор (возьмите его со старой спортивной куртки).

Материалы для работы
Дальнейший алгоритм действий должен выглядеть следующим образом.
Таблица. Делаем бумажные жалюзи
Шаги, №№
Краткое описание
Иллюстрация
Шаг 1
После выполнения замеров сделайте простую разметку – отметьте места проколов и сгибов. Далее согните обои, чтобы получилась красивая «гармошка».

Свернутое гармошкой полотно
Шаг 2
Сложите полученную заготовку в одну ровную полоску, как показано на изображении.

Складываем заготовку
Шаг 3
Проткните все слои обоев с помощью дырокола или шила.

Свернутое в одну полоску полотно протыкаем шилом
Шаг 4
Осторожно расширьте проделанное отверстие.

Делаем отверстия, расширяем их
Шаг 5
Пропустите через отверстие ленту (при желании можно заменить бельевым шнуром). При помощи этой ленты вы и будете открывать бумажные жалюзи.

Продеваем нить через отверстия
Шаг 6
Разложите «гармошку» на полу, распрямив ее.

Разворачиваем полотно
Шаг 7
Сверху завяжите шнур и зафиксируйте его с помощью скотча.

Завязываем узел
Шаг 8
Снизу отрежьте излишки шнура, оставив небольшой запас для дальнейших манипуляций.

Нижняя часть шторы
Шаг 9
Сложите жалюзи снизу таким образом, чтобы получился своего рода павлиний хвост. Это достаточно просто. Затем склейте между собой 5 последних складок и зафиксируйте посредством двухстороннего скотча.

Складываем полотно
Шаг 10
Установите на шнур фиксатор от куртки.

Установленный фиксатор
Шаг 11
Укоротите ленту до требуемой длины, конец можете украсить бусинкой.

Не делайте шнур слишком длинным
Шаг 12
Прикрепите готовые жалюзи к окну, используя все тот же двухсторонний скотч.

Используем двухсторонний скотч для фиксации полотна

Бумажные шторы на окне
Такие жалюзи будут выглядеть свежо и оригинально, ничем не уступая своим «магазинным» аналогам. Существуют и другие разновидности этих изделий – к примеру, с несколькими параллельными шнурами.
Видео – Бумажные жалюзи
Вариант №3. Делаем японские шторы
Отличный вариант для украшения просторных балконов и лоджий. Изготовление таких занавесок изначально подразумевало применение только натуральных тканей – льна или хлопка. Если же ваш бюджет сильно ограничен, то отдавайте предпочтение не растягивающимся материалам. И еще один важный момент: поверхность японских штор должна быть идеально гладкой, без волн или складок.

Красивые японские шторы

Шторы в интерьере
Вначале выполните крой панелей, действуя по приведенной ниже инструкции.

Материалы для работы
Шаг 1. Замерьте ширину оконного проема, полученную цифру разделите на 60 см. Так вы определите требуемое число панелей. И если ширина делится на 60, значит, панели будут устанавливаться вплотную друг к другу. Если же она не кратна 60-ти, то округлите в большую сторону с целью последующего перекрытия панелей.
Шаг 2. Отмерьте высоту от карниза, к полученному значению добавьте еще 10 см (для припусков).
Шаг 3. Умножьте полученную длину на число панелей – это позволит узнать требуемую длину ткани, если ширина 60 см. При большей ширине длина уменьшается пропорционально.
Шаг 4. Выкройте панели на куске материала, обработайте нижний и боковые края.

Подшиваем боковые швы
Шаг 5. Разгладьте панели, после чего обработайте верхнюю часть. Планка, которая будет закреплена к карнизу, должна иметь липучку (последнюю называют велкро).

Хорошенько разглаживаем, чтобы шторы не сборили

Размечаем складки

Делаем строчку

Складываем ткань

Пришиваем липучку
После этого можете приступать непосредственно к пошиву – для этого:
- разгладьте велкро;
- уложите штору так, чтобы был виден верхний край;
- приложите велкро на припуск передней стороной и прикрепите булавками;
- пристрочите все;
- уложите штору, отогните велкро к изнанке;
- закрепите все булавками и прострочите;
- отутюжьте ткань, чтобы она получилась идеально гладкой;
- внизу сделайте кулиску, в нее вставьте утяжелитель;
- вставьте верхнюю часть в держатель.

Окрашиваем планку-карниз

Крепим планку

Крепим на ребро липучку

Фиксируем шторы
Видео – Японские панели
Вариант №4. Изготавливаем нитяную штору
Подобный декор выглядит эффектно, поэтому может стать истинным украшением вашего балкона. При желании эту занавеску можно изготовить в домашних условиях.

Нитяная штора
Для работы подготовьте:
- плотную пластиковую планку (еще она может быть деревянной или картонной) требуемого размера;
- широкую ткань для декора планки;
- нитку толщиной минимум 0,2 см;
- молоток;
- клеевой пистолет;
- зажигалку;
- тонкие гвозди (5-6 штук) для того, чтобы прикрепить планку к проему.

Инструменты и материалы для работы
После подготовки начинайте работы по изготовлению штор-нитей.
Шаг 1. Измерьте высоту оконного проема. Длина одной нити будет состоять из высоты проема, умноженной на 2, ширины планки, умноженной на 4, и 2 см запаса. К примеру, если высота проема равна 1,5 м, а ширина планки составляет 2 см, то длина одной нити составит 3,1 м.
Шаг 2. Нарежьте куски нити требуемого размера. Заранее посчитайте, сколько таких кусков понадобиться, но ориентировочно это 400-500 штук. Для удобства можете выполнять работу этапами: нарезать, к примеру, сотню нитей – прикрепить и т. д.
Шаг 3. Прикрепите нити к планке. Делайте это обычным узлом, так же, как в макраме: один отрезок сложите вдвое, перекиньте через планку, а через петлю, которая образовалась, проденьте концы. Для фиксации петли используйте клеевой пистолет. Ниже продемонстрировано, как нужно правильно крепить нити.

Фиксация нитей на планке

Схема крепления нитей
Шаг 4. Распределите все нити равномерно, после чего замаскируйте просветы, сквозь которые видна планка (делайте это тонкой спицей либо руками). После этого осторожно подровняйте отрезки.
Шаг 5. Концы нитей опалите зажигалкой – так изделие прослужит дольше. Как вариант – можете окунуть концы (максимум 0,5 см) в клей.
Шаг 6. Торцы планки можно скрыть кусками ткани, прикрепленными степлером или клеем и подогнутыми на изнаночную часть (ту, что будет закреплена к стене).

Изготовление нитяных занавесок
Обратите внимание! При желании можете надеть на нити бусинки – так занавеска будет выглядеть еще привлекательнее.
Шаг 7. Остается лишь прикрепить готовую занавеску к проему. Используйте для этого маленькие отделочные гвозди. Все, работа закончена.
Такие шторы могут украсить не только балкон, но и любую другую комнату. Еще они будут превосходно смотреться на дверях или окнах загородного дома.

Готовая нитяная штора

Нитяные и веревочные шторы в интерьере

Нитяные шторы можно скрепить простым зажимом
Видео – Нитяные шторы в дизайне интерьера











| « Апрель 2024 » | ||||||
|---|---|---|---|---|---|---|
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | |||||

